
What is data matching?
Data matching (also known as record linkage or entity resolution) is the process of comparing and identifying similarities or relationships between datasets to determine if two records are talking about the same real-world thing (also called an entity).
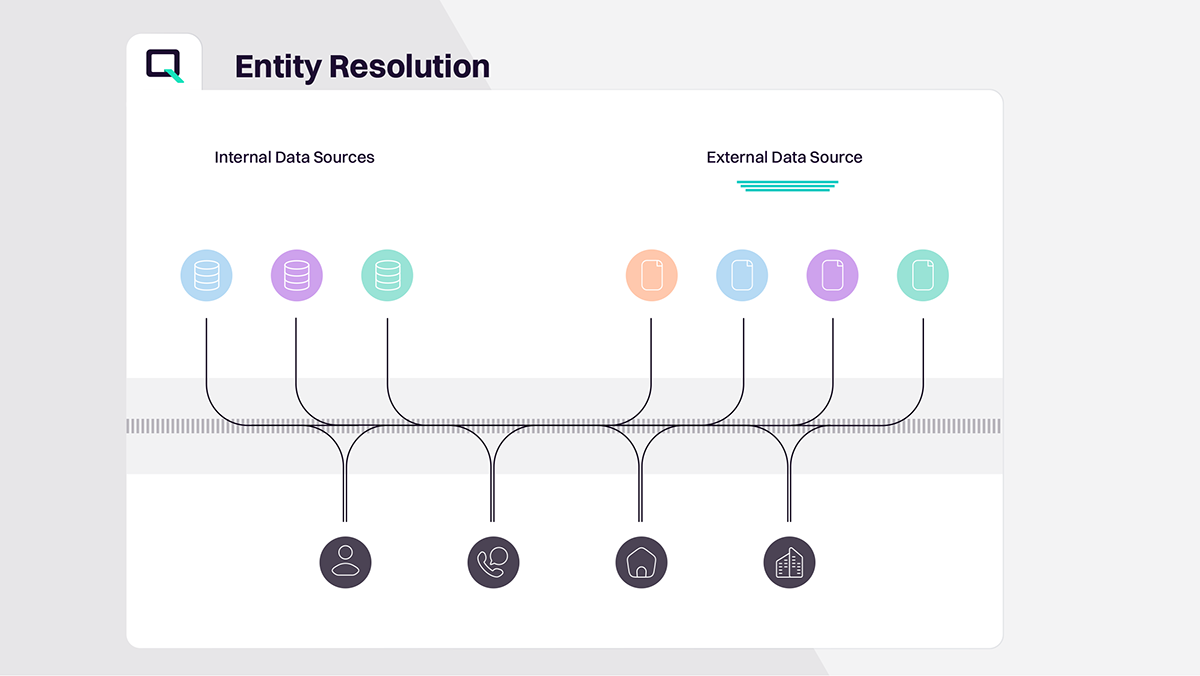
Entity resolution connects information from different datasets to identify and link records that belong to the same entity or individual. It's essential in scenarios like merging customer profiles or healthcare record management.
It involves comparing information from different sources or within a single dataset to find commonalities, overlaps, or connections.
Data matching typically involves algorithms or methodologies that analyze various attributes or fields within datasets, seeking matches based on predefined criteria. This can include exact (or strict) matches, fuzzy logic for approximate matches, or sophisticated algorithms that account for variations in data format, structure, or quality.

What is the purpose of data matching?
The primary goal of data matching is to consolidate, reconcile, or link disparate datasets to reveal patterns, associations, or duplicates. It helps in identifying redundancies, ensuring data integrity, improving data quality, and facilitating better decision-making processes across various domains, including finance, healthcare, telecoms, insurance, and more.

What are the different types of data matching?
Data matching techniques vary based on the nature of the data and the intended outcomes. Common methods include deterministic matching (exact matches) and probabilistic matching (likelihood of matches based on criteria). Modern solutions use advanced techniques employing machine learning, artificial intelligence, or pattern recognition for complex matching scenarios.
The types of data matching:

Deterministic matching
Also known as record-to-record matching. This method involves exact comparisons between fields or attributes in datasets to find identical matches. It's precise and commonly used when data elements are consistent and well-structured.
Probabilistic matching
Unlike deterministic matching, this approach considers the likelihood of matches based on predefined criteria or rules. It's useful when dealing with inconsistent or incomplete data where exact matches might not be available.
How does data matching work?
Data matching, also known as record linkage or entity resolution, focuses on identifying and linking records that refer to the same real-world entity across disparate datasets. It involves resolving references to entities (such as individuals, products, or organizations) to merge or link related records.
The process can be broken down into these main steps:
- 1. Data preparation
Data undergoes preprocessing steps like standardization, cleaning, and normalization to ensure consistency across datasets. This involves handling variations in data formats, correcting errors, and formatting data fields for uniformity. There are schema-less solutions on the market which automate this step using AI and they significantly reduce the otherwise lengthy preparation time.
- 2. Feature extraction
Relevant features or attributes, such as names, addresses, IDs, or other identifying information, are extracted from the datasets. These features serve as the basis for comparison during the matching process.
- 3. Similarity calculation
Entity resolution involves calculating the similarity or distance between pairs of records based on their extracted features. Various similarity metrics (e.g., Jaccard similarity for text, distance metrics for numerical values) are used to quantify how closely records match.
- 4. Matching strategy
A matching strategy or threshold is established to determine when records are considered a match based on the calculated similarities. This strategy could be based on predefined rules, machine learning models, or statistical techniques.
- 5. Resolution and linkage
Once potential matches are identified, decisions are made on how to resolve these matches. This might involve merging records, creating links between related records, or flagging potential matches for further human review or confirmation.
What is the difference between data matching and data mining?
Data matching and data mining are both essential processes in the realm of data analytics and management. While data matching focuses on matching or linking data elements, data mining delves deeper into uncovering hidden patterns or knowledge from data, serving distinct but complementary purposes in data analysis.

What are the benefits of data matching?
With effective data matching, organizations can build a trusted data foundation and get insights for confident decision-making.
Here are some benefits of data matching:
Data accuracy and quality
Data matching ensures that duplicate or related records representing the same real-world entity are correctly identified and linked. This process improves data accuracy by eliminating redundancies and inconsistencies, thereby enhancing overall data quality and integrity.
360-degree view of data
By connected disparate data, entity resolution enables the creation of unified views of entities (such as customers, patients, products) scattered across various sources. This comprehensive view provides a holistic understanding, facilitating better decision-making and analysis
Confident decision-making
A consolidated and accurate view of entities obtained through entity resolution supports more informed and data-driven decision-making. Organizations can derive deeper insights, identify patterns, and make better predictions by accessing a complete and coherent representation of entities.
Operational efficiency
Efficient entity resolution streamlines processes by reducing data redundancy and ensuring consistency across datasets. This optimization leads to improved operational efficiency, reduced processing times, and minimized errors in tasks reliant on accurate data.
Gain control of your data

Why do organizations need to consider data matching?
Organizations need to consider data matching or, in other words, building trusted views of their data to avoid the following implications:

Your records are incomplete and may include outdated, inaccurate information.

Your team offers services and products to customers who already have them.
Your customers get frustrated repeatedly sharing details and information to different customer service agents operating in different data silos.

Your data teams are overloaded with mounting manual tasks.

Customer experience takes a nosedive, due to inaccurate, missing or misrepresented information.
Big revenue opportunities and potential risks are overlooked.
What are the industry use cases of data matching?
Data matching plays a pivotal role across industries, from enhancing service delivery and customer experiences to ensuring regulatory compliance and improving decision-making processes. Its applications in government, healthcare, banking, insurance, and telecommunications underline its significance in optimizing operations and deriving valuable insights from disparate datasets.
Here’s what a single view of your customer, patient, or citizen will help you to achieve across different industries:
Insurance
Better data can help you improve your Combined Operating Ratio by improving loss ratios through better underwriting and claims decisions, increasing customer value through better insights, and automating straight-through claims and low-touch applications. Proactive monitoring also enables quicker identification and mitigation of risk exposures.
Banking
Building a strong data foundation is key to understanding customer behaviors and mitigating the risks of fraud and other financial crimes. Automate your KYC and AML processes, develop context to quickly detect and prevent fraud at scale, and optimize
operations to improve holistic customer experiences.
Telecommunications
A trusted data foundation helps you gain a competitive advantage by building and understanding changing customer networks and behaviors. Unlock insights that accelerate growth and revenue, all while protecting customers, suppliers, and employees from fraud
and facilitating compliance.
Government and Public Sector
Accurate and connected data drives a range of efficiencies, including faster and more intuitive investigations, enhanced information-sharing and cross-agency collaboration, and protection of citizens and data from previously unknown risks.
Fragmented and siloed data undermines the work of government organizations, no matter their mission.
Healthcare
A single-patient view to elevate patient care, automate processes, make information more accessible and shareable between practitioners and patients, and empower organizations to use data proactively to plan for patient needs.
What are the challenges of data matching?
Challenges in data matching include dealing with data inconsistencies, handling large volumes of information efficiently, maintaining privacy and security, addressing variations in data formats, and managing computational complexities in matching diverse datasets.
Scalability
Entity resolution poses significant scalability challenges, especially when dealing with large volumes of data. Processing extensive datasets requires robust computational resources and efficient algorithms to perform comparisons and match records effectively.
Variability
Data inconsistencies, variations in formats, and incomplete or conflicting information across datasets can introduce ambiguity during entity resolution. Variances in data representations or the absence of standardized formats can hinder accurate matching.
Computational complexity
Computational complexity of entity resolution increases with the number of records and features to be matched. Algorithms must efficiently process and compare diverse data attributes, impacting the time and resources required for resolution.
Matching accuracy
For match results to be effective, the accuracy must be 80% or higher. However, with data often is trapped in silos across internal and external systems without common linking keys, is of poor quality and misses information. Moreover, geographical variations in languages, scripts, name structures and address formats make it extremely difficult to match correctly.
Quality gating
Many data matching engines will require so much data preparation to be able to ingest it into the system, it may rule out a large number of data sources that do not fit the bill. Organizations report that the data preparation step sometimes takes so long that by the time it is ingested, business objectives have changed and it is no longer needed.
Key takeaways
Data matching plays a crucial role in enhancing the accuracy, reliability, and usefulness of data by identifying relationships and connections between disparate datasets. It forms the foundation for informed decision-making and enables businesses and organizations to derive valuable insights from their data assets.
Useful links
We’ve discussed a lot in this guide, but there might still be more you want to discover about data matching. Browse these handy sources to learn more.